Track 1 - EmpathyEval
Evaluation of Contextualized Affective Speech
This track evaluates whether omni-models can identify the most appropriate spoken response by combining contextual understanding with affective and paralinguistic reasoning, advancing AI capabilities for empathetic perception in speech.
Task Description
Given a textual context and an audio utterance, with a set of candidate audio responses, select the response that is most empathetic.
Evaluation compares participant predictions against human annotations, so the benchmark emphasizes human-aligned response selection rather than literal semantic overlap alone.
Subtasks
Task 1: Context-Variant
The surrounding conversational context changes, indicating different situations, and the model must determine which candidate response best fits the specific situation.
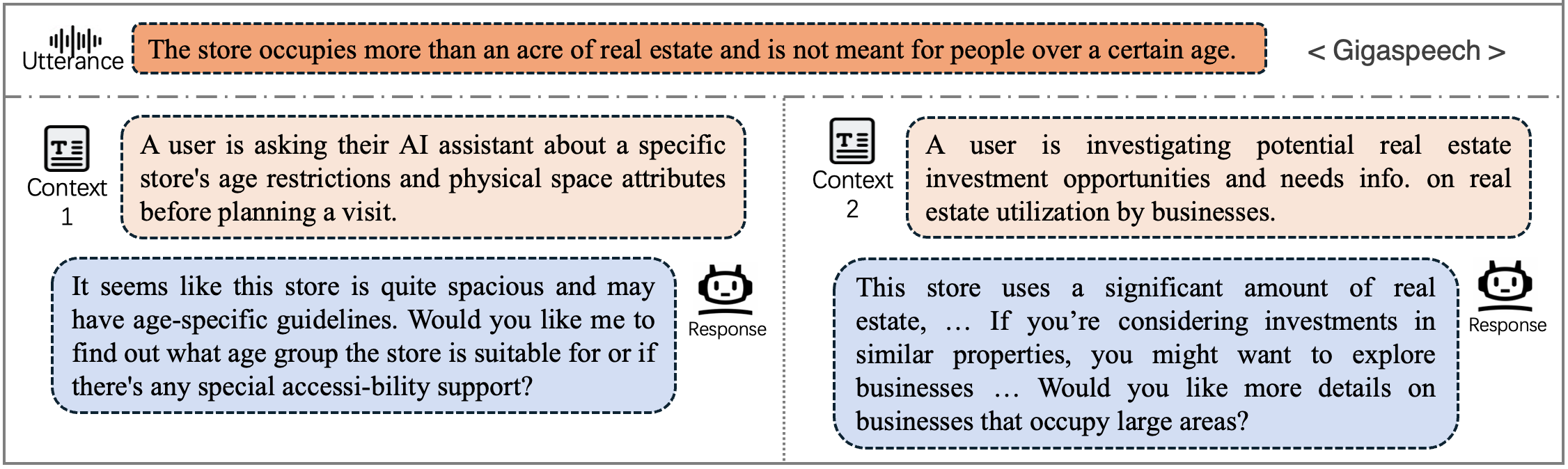
Data Example (Audio and textual context)
|
Context 1
During a bachelorette weekend, their friends surprised them with a spa package that included a manicure, and they’ve never been to a nail salon before. |
Context 2
After losing a fantasy football bet, the agreed penalty was to get a bright, glittery manicure and keep it for a week. |
|
Utterance Audio
|
|
|
Candidate Responses
A
B
✓
|
Candidate Responses
A
B
✓
|
Task 2: Tone-Variant
The model must rely on vocal and paralinguistic cues of the utterance to infer the inner state or emotion of the user, and identify which response is emotionally appropriate for the given utterance.

Data Example (Audio and textual context)
|
Context
While helping my mom clear out the guest room before her knee surgery, I pulled out a dusty box labeled "1996-2002" packed with camp Polaroids and birthday party prints. I brought the stack home to sort through after dinner a few nights later. |
|
|
Utterance Audio: tone 1
|
Utterance Audio: tone 2
|
|
Candidate Responses
A
✓
B
|
Candidate Responses
A
✓
B
|
Evaluation Metrics
- Accuracy: for each correctly predicted item, the accuracy score increases by 1.
- Grouped bonus: if all items in a context-variant or tone-variant group are predicted correctly, the bonus score increases by 1.
- Final Score:
(Accuracy + Bonus) / (#data + #group).
Dataset
Phase 1 Test Set:
1) multi-context_gigaspeech, 2) multi-context_meld, and 3) multi-emotions_emovdb
Please download the training set for each subtask from Hugging Face:
1) empatheticDialogue_n_multi-emotion and 2) empatheticDialogue_t_multi-context
Leaderboard
The leaderboard will report context-variant and tone-variant results separately, Accuracy / Bonus / Final Score, together with the weighted average of the final scores.
| Rank | Model | Context-variant | Tone-variant | Avg. |
|---|---|---|---|---|
| 1 | HumOmni_Nexus | 358 / 125 / 0.833 | 98 / 11 / 0.727 | 456 / 136 / 0.811 |
| 2 | 111 | 339 / 116 / 0.784 | 113 / 23 / 0.907 | 452 / 139 / 0.810 |
| 3 | smalltry | 339 / 115 / 0.783 | 101 / 16 / 0.780 | 440 / 131 / 0.782 |
| 4 | 19191 | 313 / 100 / 0.712 | 109 / 19 / 0.853 | 422 / 119 / 0.741 |
| 5 | Lenormand_Team | 303 / 103 / 0.700 | 106 / 16 / 0.813 | 409 / 119 / 0.723 |
| 6 | WhereIsAI-Lingnan | 289 / 84 / 0.643 | 108 / 19 / 0.847 | 397 / 103 / 0.685 |
| 7 | tryanderror2 | 232 / 67 / 0.516 | 95 / 5 / 0.667 | 327 / 72 / 0.547 |
| 8 | HumOmni_H | 235 / 53 / 0.497 | 79 / 4 / 0.553 | 314 / 57 / 0.508 |
| (baseline) | Qwen2.5-Omni-7B | 189 / 32 / 0.381 | 60 / 3 / 0.420 | 249 / 35 / 0.389 |
| (baseline) | Qwen2.5-Omni-3B | 182 / 31 / 0.367 | 66 / 3 / 0.460 | 248 / 34 / 0.386 |
Public scores are announced after the evaluation process. Current scores are submissions by Jun 22, 20:00 GMT+8.