Track 2 - ProactivEval
Evaluation of Vision-Grounded Proactive Interaction
This track aims to advance AI capabilities for proactive perception in visual streams by evaluating whether models can serve as proactive and helpful embodied assistants. We assess their capacity to interpret context, anticipate needs, and support humans proactively, timely and helpfully in several real-world, vision-grounded scenarios.
Task Description
Given a real-time playing video stream and a question provided at the beginning of the video, participants are required to develop models that can proactively decide when to respond and what to respond to during video playback, rather than replying after explicit user queries.
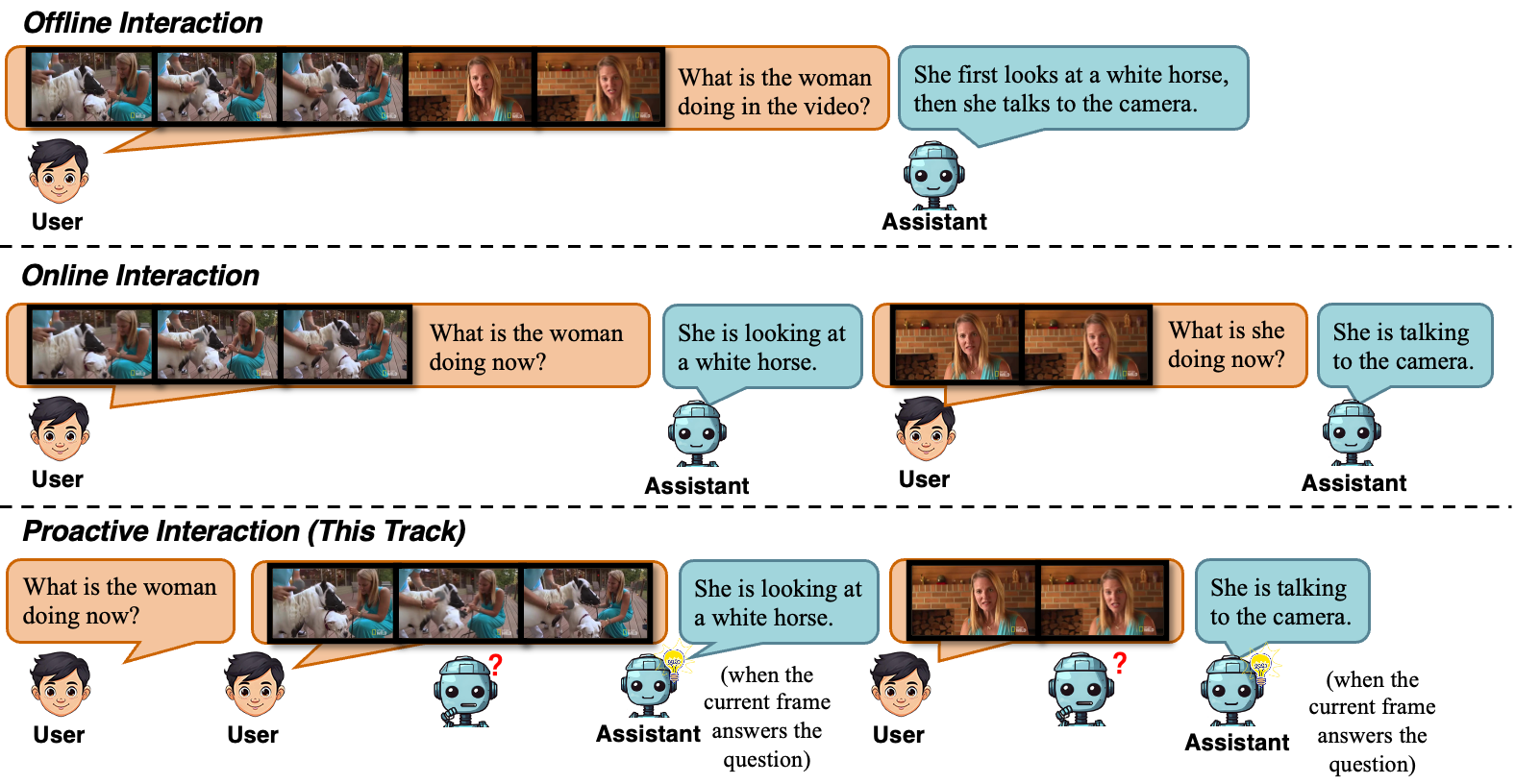
Participants will be invited to submit a dialogue system, including a multimodal LLM and the corresponding inference code. The input of the system will be a question at the beginning of the video, and frame-by-frame input of a video. The system should be able to determine whether to generate a response and what the response should be after each frame input, based solely on the context observed so far. When generating responses at time t, using frames after time t is strictly prohibited.
The ground truth for each test example contains one or more responses. Each ground truth response consists of a timespan and a corresponding text.
Example video: (the question and answers are illustated in the videos as subtitles. The subtitle beings with "[0s] user:" is the question, and subtitles begin with "[t1-t2] assistant:" are ground truth answers.)
Evaluation Metrics
Models will be evaluated on timeliness, correctness, and redundancy.
The model will be evaluated using two LLM-based metrics: PAUC ( in [0, 1], higher is better) and duplicate ( in [0, 1], lower is better). PAUC requires the model to generate content as early as possible within the timespan that is as semantically similar as possible to the reference text. This metric measures both timeliness and correctness of a model. For a detailed explanation of the PAUC metric, please refer to the ProactiveVideoQA arXiv paper.
The duplicate metric requires that the model does not generate identical responses to existing ones within the same timespan. This metric measures the redundancy of a model. It is defined as follows: for each timespan, starting from the second response, we determine whether each subsequent response is fully entailed by all prior responses within the same timespan. The ratio of the number of such true entailment cases to the total number of responses after the first one in the timespan is taken as the duplicate score. A lower value indicates better performance.
For both metrics above, text similarity will be computed using an LLM (Gemini 3.1 Flash-Lite).
The ranking will be based on a weighted sum of the two metrics:
0.9 × PAUC + 0.1 × (1 − duplicate)
Dataset
Phase 1 Test Set:
We do not provide an official training set, but you can obtain training data from the following related works on proactive interaction:
https://github.com/showlab/videollm-online
Leaderboard
| Rank | TeamID | PAUC | repetition | Overall Score |
|---|---|---|---|---|
| 1 | tryanderror2 | 58.93 | 1.49 | 62.89 |
| 2 | TryTry | 61.24 | 34.46 | 61.67 |
| 3 | smalltry | 56.77 | 8.89 | 60.21 |
| 4 | momoEng | 36.26 | 0.05 | 42.63 |
| (baseline) | MMDuet2 | TBA | TBA | TBA |
Public scores are announced after the evaluation process. Current scores are submissions by Jun 22, 20:00 GMT+8.